Why Error Analysis?
Error Analysis is a Responsible AI toolkit that enables you to get a deeper understanding of machine learning model errors. When evaluating a machine learning model, aggregate accuracy is not sufficient and single-score evaluation may hide important conditions of inaccuracies. Use Error Analysis to identify cohorts with higher error rates and diagnose the root causes behind these errors.
Evaluate Cohorts
Learn how errors distribute across different cohorts at different levels of granularity
Explore Predictions
Use built-in interpretability features or combine with InterpretML for boosted debugging capability
Interactive Dashboard
View customizable pre-built visuals to quickly identify errors and diagnose root causes
How Error Analysis Works
Identification
Error Analysis identifies cohorts of data with higher error rate than the overall benchmark. These discrepancies might occur when the system or model underperforms for specific demographic groups or infrequently observed input conditions in the training data.
Different Methods for Error Identification
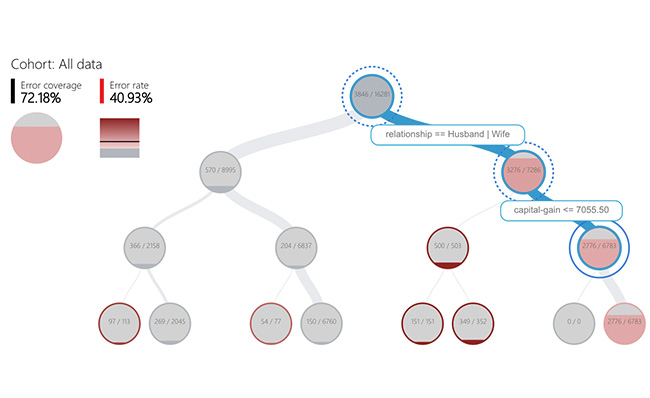
Decision Tree
Discover cohorts with high error rates across multiple features using the binary tree visualization. Investigate indicators such as error rate, error coverage, and data representation for each discovered cohort.
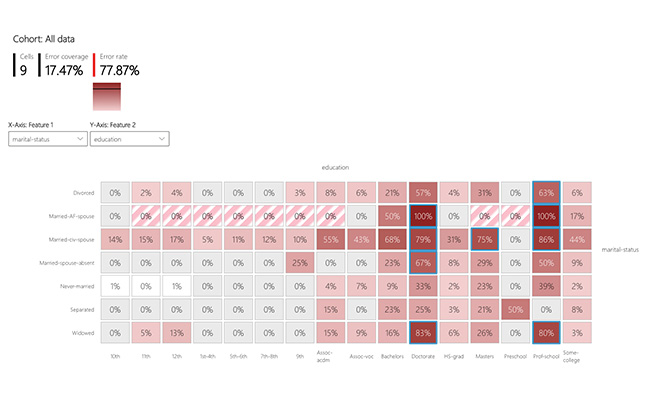
Error Heatmap
Once you form hypotheses of the most impactful features for error, use the error heatmap to further investigate how one or two input features impact the error rate across cohorts.
Diagnosis
After identifying cohorts with high error rates, Error Analysis enables you to understand the reasons behind the error rates so you can take corrective actions.
Different Methods for Error Diagnosis
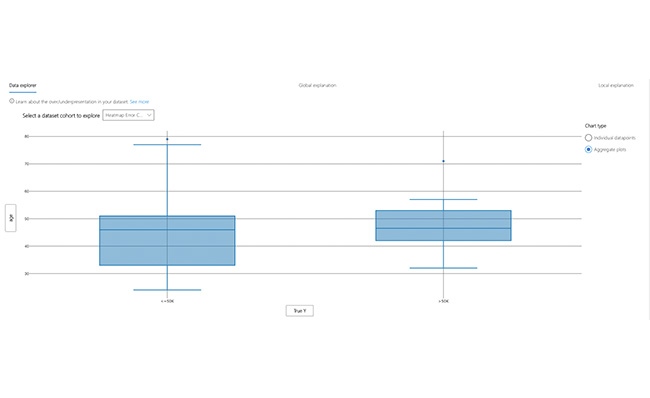
Data Exploration
Explore dataset statistics and feature distributions. Compare cohort statistics with other cohorts or to benchmark. Investigate whether certain cohorts are underrepresented or their feature distribution is significantly different from the overall data.
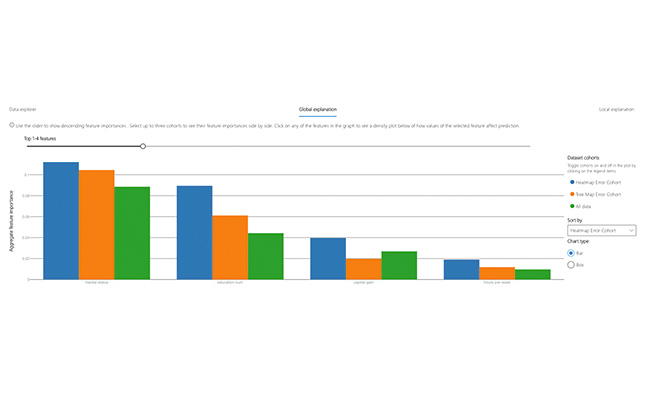
Global Explanation
Explore the most important features that impact the model global explanation of a selected cohort. Understand how values of features impact model predictions. Compare explanations of your selected cohorts with other cohorts or benchmark.
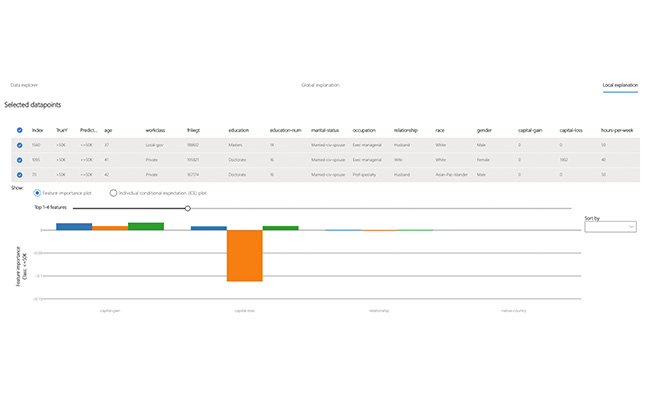
Local Explanation
Analyze the selected cohort's datapoints in instance view, divided by correct or incorrect predictions. Visually examine for missing features or label noises as potential causes for incorrect predictions. Understand which features have the most impact to each data point's predictions. Observe individual conditional expectation plots.
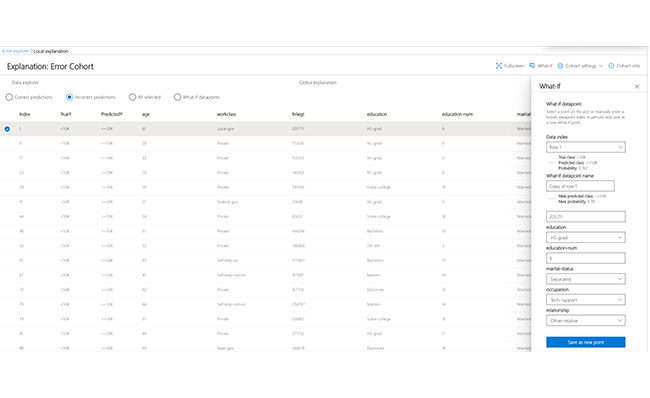
What-if Analysis
Apply changes to feature values of a selected data point and observe the resulting change to the prediction.
Getting Started
Install Error AnalysisContribute To Error Analysis
We encourage you to join the effort and contribute feedback, algorithms, ideas and more, so we can evolve the toolkit together! Example contributions may include novel visualizations, failure explanation algorithms, improved UX experience, or further integration with other toolkits in Responsible AI.
Explore other Responsible AI toolkits
Assess fairness & mitigate unfairness using Fairlearn
Understand model behaviors using InterpretML